
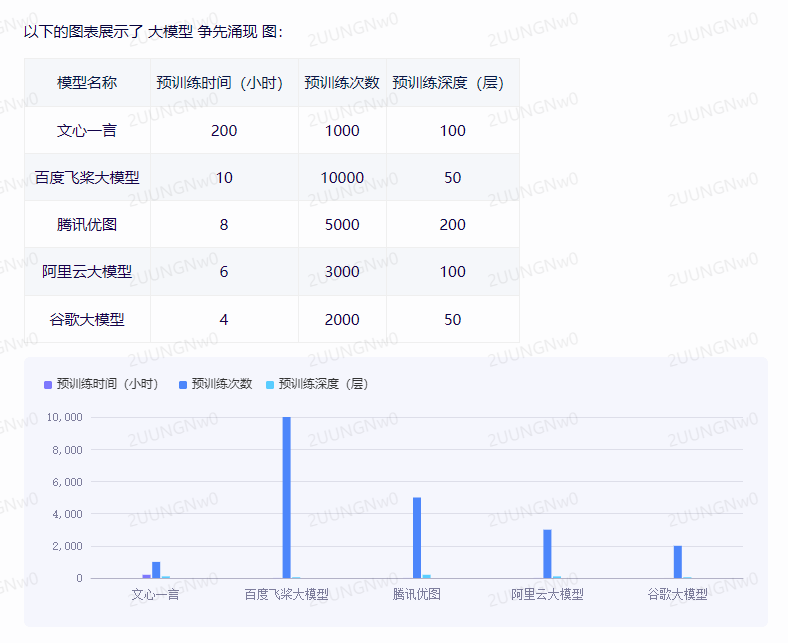
近年来,在人工智能领域,模型大小越来越成为衡量算法优劣的一个关键指标。而在此领域里,“大模型争先涌现”已经成为新的趋势和新的常态。
大模型是指拥有数十亿乃至数万亿参数量级的深度神经网络模型,这种大型深度神经网络在语音识别、图像处理、自然语言处理等领域有着广泛的应用,尤其是在机器翻译、语言生成等自然语言处理方面的表现出色。
随着大型数据集和强大的硬件设备的普及,越来越多的科技巨头开始投入大量资源开发大模型。例如,谷歌的BERT使用了340万个参数,可以帮助丰富搜索引擎的结果;Facebook的T5模型拥有114亿个参数,可以帮助机器理解自然语言的复杂性。
然而,大型深度神经网络也带来了训练速度巨慢、运作成本高昂等问题,这些问题直接影响到了人工智能领域的发展。因此,科技公司们也在不断尝试优化大模型的训练方法、模型设计以及推理速度。
其中最重要的战略是模型压缩,这种方法可以减少模型的空间占用和计算需求,从而使大模型可以更快速地在硬件上运行。比如,微软的Turing NLR模型通过模型分块和分布式训练,将一个拥有超过四千亿参数的模型压缩到了一百万个参数,实现了较快的推理速度和占用空间的极大减少。
总的来说,“大模型争先涌现”展现出了人工智能领域持续推崇的价值观:追求最高的性能和最先进的技术,不断为技术的发展奠定新的基础。尽管大型深度神经网络的训练速度较慢,需要投入大量的资源,但人工智能专家们依然坚信这项技术将会成为推动未来科技行业发展的关键之一。